深度学习中的优化问题通常指的是:寻找神经网络上的一组参数θ,它能显著地降低代价函数J(θ)。针对此类问题,研究人员提出了多种优化算法,Sebastian Ruder 在《An overview of gradient descent optimizationalgorithms》(链接:https://arxiv.org/pdf/1609.04747.pdf )这篇论文中列出了常用优化算法的比较。主要优化算法有:BGD、SGD、Momentum、Adagrad、Adadelta、RMSProp、Adam。
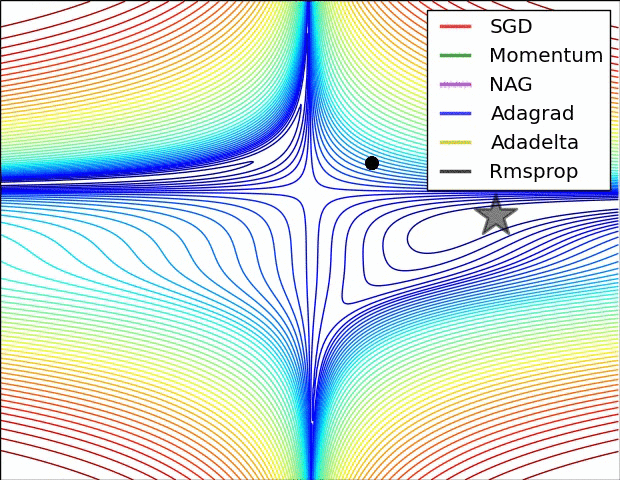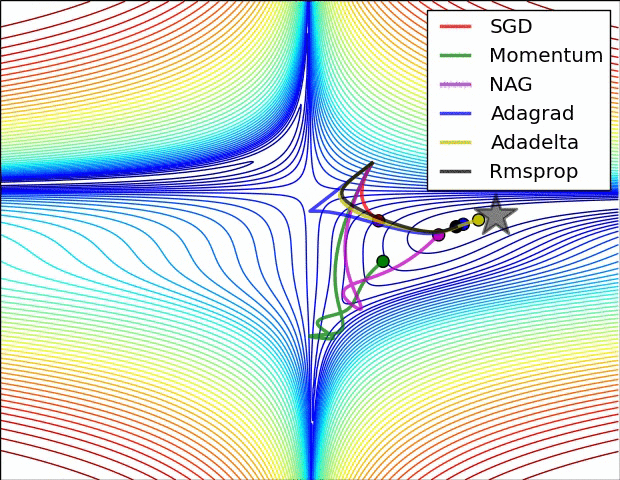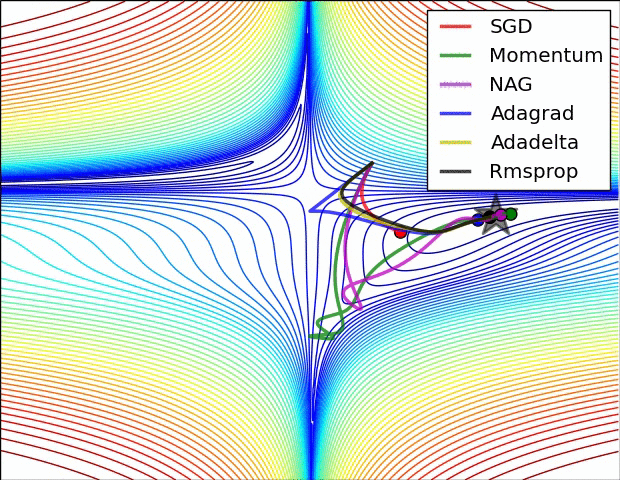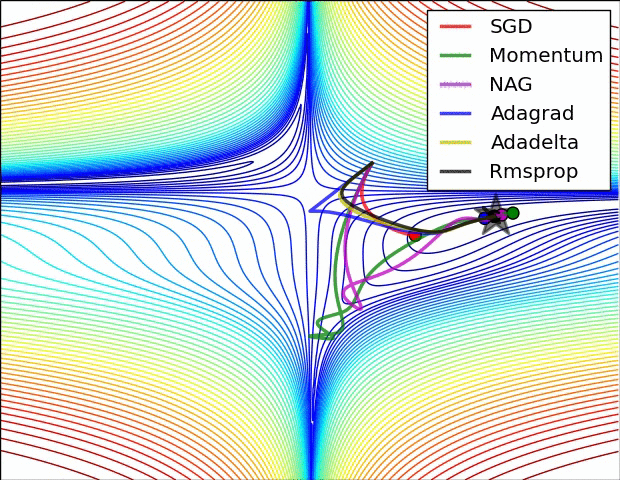
优化算法简单介绍
BGD:批量梯度下降,每次迭代采用整个训练集数据来计算损失函数J(θ)对参数θ的的梯度。
SGD:随机梯度下降法,用单个训练样本的损失来近似平均损失。
Momentum:动量算法。
Adagrad:是一种可以自动改变学习速率的优化算法,只需设定一个全局学习速率ϵ。
Adadelta:adagrad算法的延伸和改进,
RMSProp:自适应学习率方法,引入一个衰减系数ρ,让r每次都以一定的比例衰减,类似于Momentum中的做法。
Adam(Adaptive Moment Estimation):Momentum+RMSProp,带有动量项的RMSProp算法。
参考文档
https://zhuanlan.zhihu.com/p/55150256
https://zhuanlan.zhihu.com/p/43506482
https://www.cnblogs.com/54hys/p/12340332.html
https://www.cnblogs.com/zingp/p/11352012.html
本文为 陈华 原创,欢迎转载,但请注明出处:http://www.ichenhua.cn/read/240



