Transformer P13 解码器Masked掩码张量
对照 Transformer 架构图,解码器部分的词嵌入、位置编码跟编码器结构是完全一样的,代码可以直接复用。接下来就是 N 个循环子层,进入子层之后第一个模块就不太一样了,虽然也是多头注意力,但多了一个前缀,叫做 Masked Mulit-Head Attention。这节课,我们先来搞清楚这个 Mask 的组成部分,以及生成方式。
组成部分
解码器 Mask 是由两部分组成的,一部分是 padding mask,很好理解,另一部分,是一个三角矩阵,下面给大家重点解析一下,为什么要做这个三角矩阵的 mask。
使用一个三角矩阵进行掩码操作,目的是为了确保解码器在生成每个位置的输出时,只依赖于已经生成的位置的输入,而不会依赖于后续位置的输入,避免利用未来的信息,保持模型的自回归性质。
首先,给出最终的 mask 示意图(关注橙色区域)
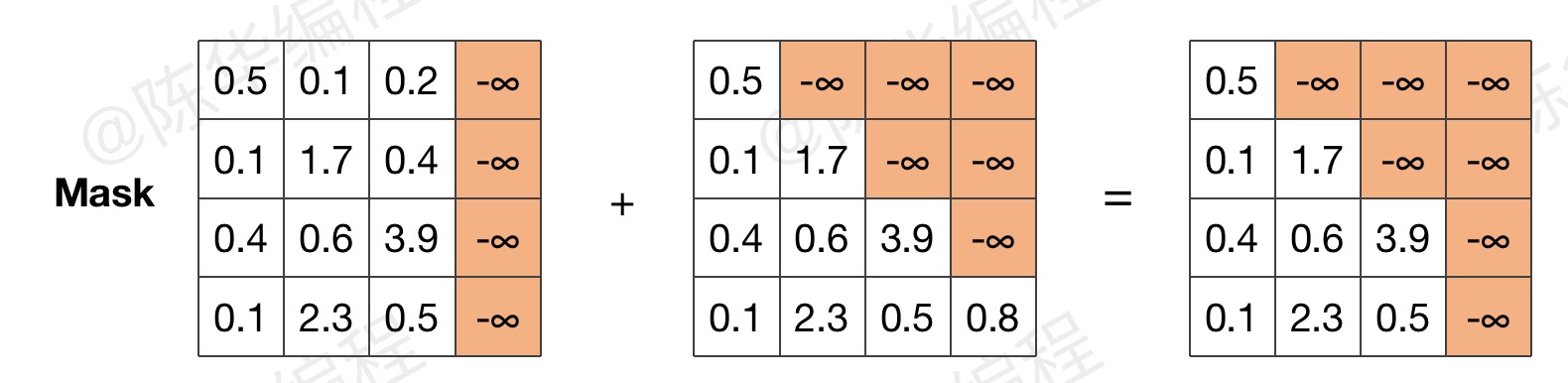
然后,观察 mask 对注意力计算的影响(忽略数值)

代码示例
1、生成三角矩阵
遮掩的位置可以是0,也可以用1,但要和 pad 规则一致,方便叠加。同时,需要注意主对角线上不能遮掩。
内容不可见,请联系管理员开通权限。
2、封装函数
内容不可见,请联系管理员开通权限。
3、和padding mask 叠加
内容不可见,请联系管理员开通权限。
在解码器的自注意力机制层,跟编码器不同的地方,就是这个 mask,他是一个带遮掩功能的 mask。
这个小功能做完之后,解码器的 N 层堆叠的结构就没什么新花样了,参数上的差异,放到下节课组装整个解码器的时候再来介绍。
本文链接:http://www.ichenhua.cn/edu/note/660
版权声明:本文为「陈华编程」原创课程讲义,请给与知识创作者起码的尊重,未经许可不得传播或转售!



