Transformer P8 Attention处理Key_Padding_Mask
上节课当中,我们实现了用于注意力计算的 attention 函数,但在函数实现过程中,忽略了一个问题,就是在NLP任务中,输入模型的句子一般都是有长有短的,为方便批处理,会强行用 pad 填充到等长。
而填充的 pad 经过词嵌入和位置编码层,会被编码成一个正常的特征向量,为了防止 pad 影响计算结果,需要把 pad 对应位置的数值 mask 掉。
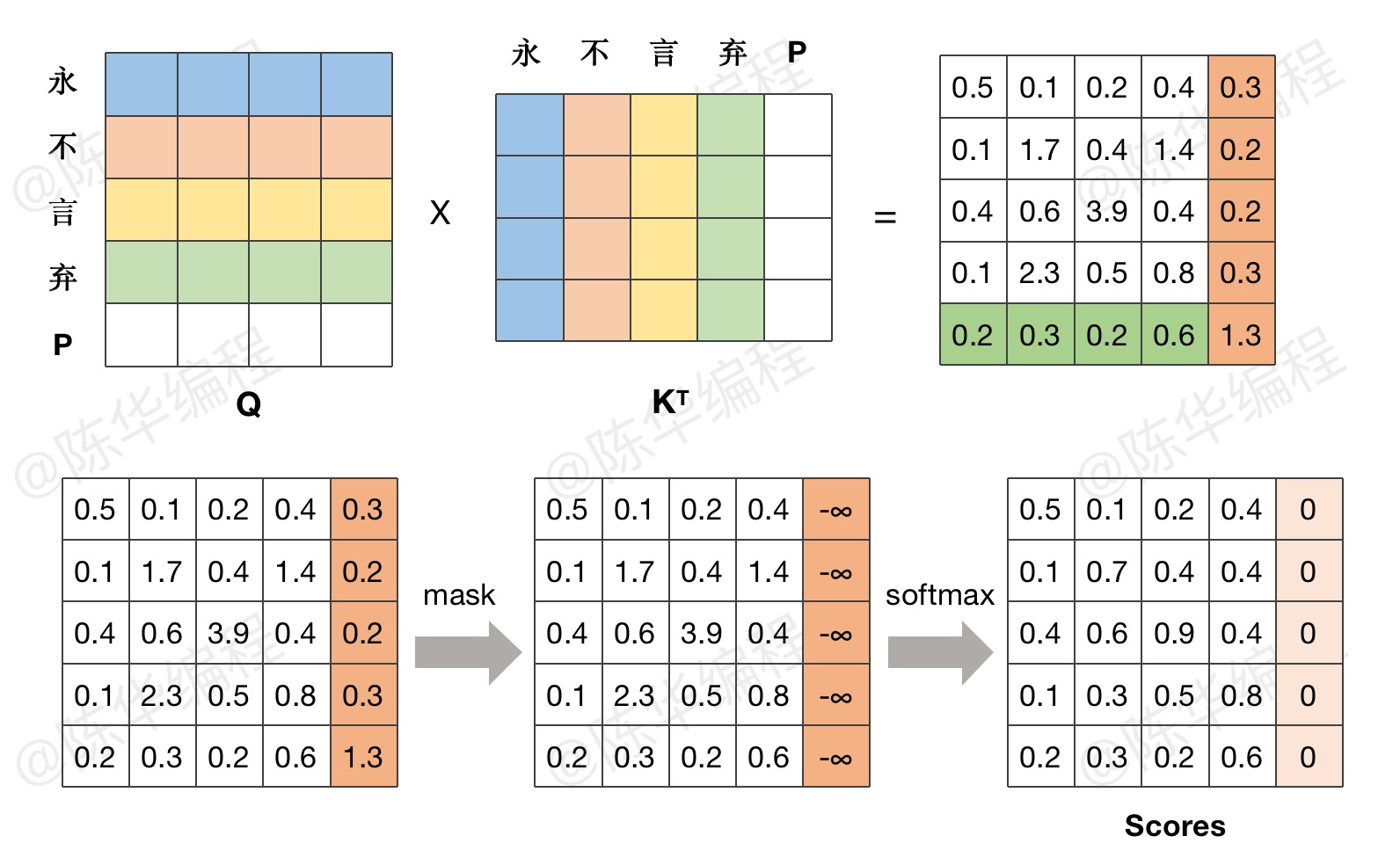
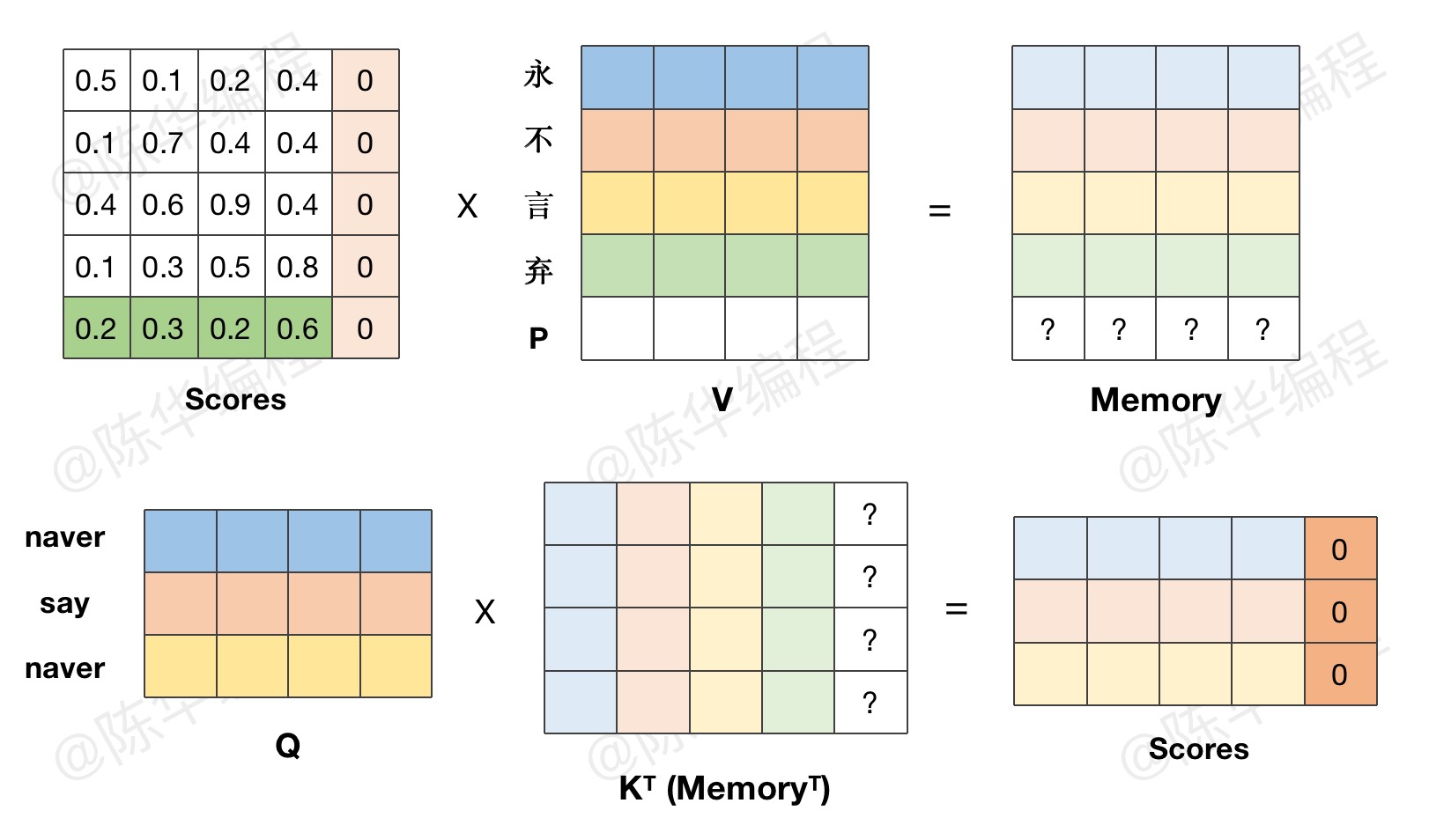
需要注意的是,在代码实现环节,我们仅考虑 key 的 pad 位置,query 的填充,会在 decode 环节被 mask 掉。
代码示例
1、masked_fill 方法
填充的位置可以是0,也可以用1,masked_fill 注意对应即可。
内容不可见,请联系管理员开通权限。
2、封装函数
内容不可见,请联系管理员开通权限。
3、attention 函数添加 mask 参数
内容不可见,请联系管理员开通权限。
好的,那现在我们就一起完成了 Multi-Head Attention 中的,Attention 的代码实现,下节课就开始处理前面的 Multi-Head 部分。
本文链接:http://www.ichenhua.cn/edu/note/655
版权声明:本文为「陈华编程」原创课程讲义,请给与知识创作者起码的尊重,未经许可不得传播或转售!



