Transformer P3 结合数据详解模型结构
上节课当中,对照论文中的模型结构图,给大家整体介绍了 Transformer 模型的各个组成部分。但是只看图的话,还是很难对模型有直观的认识,下面我想结合翻译任务中的一条样本,再给大家从数据的角度,拆解一下模型的细节。
Transformer 模型的论文标题叫做《Attention Is All You Need》,也就说明,Attention是这个模型的重点和难点,重点关注几个 Attention 部分就可以了。
论文地址:https://arxiv.org/abs/1706.03762
细节拆解
1、整体目标
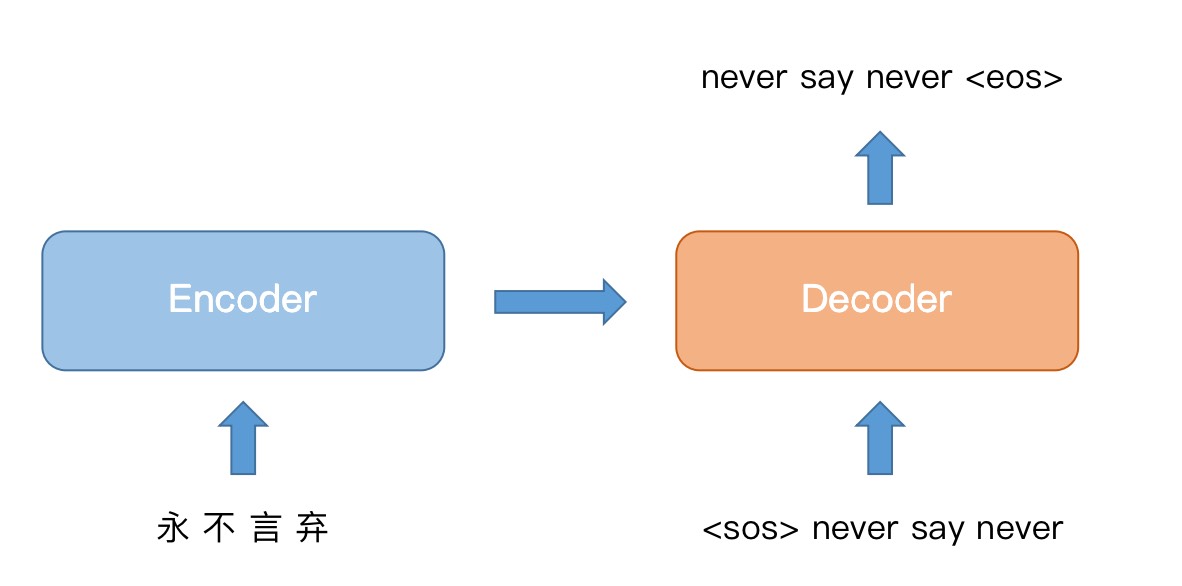
2、Embedding
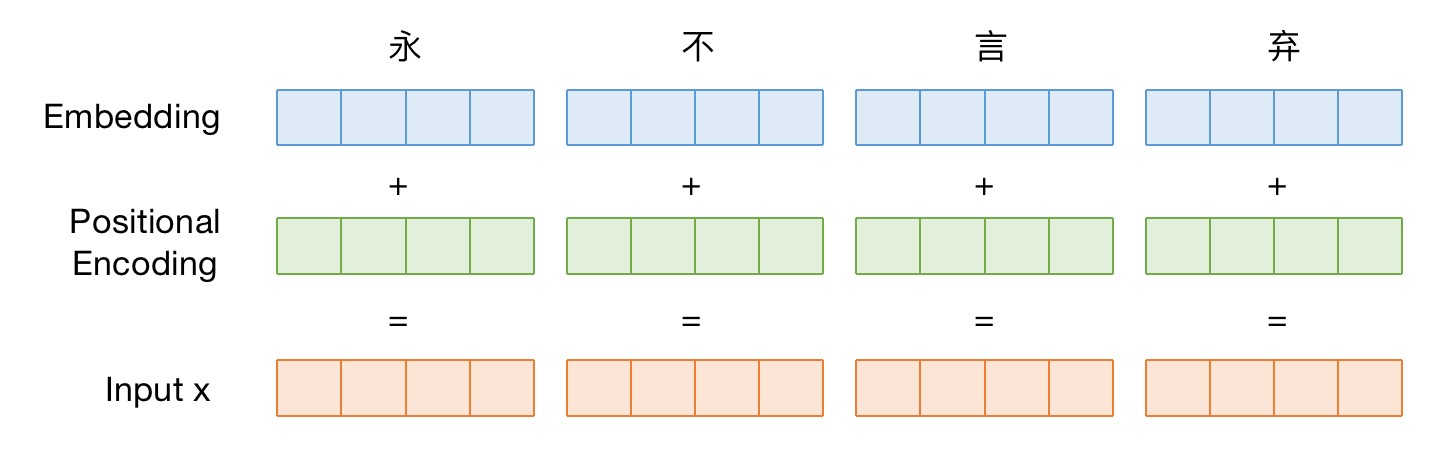
3、Self Attention
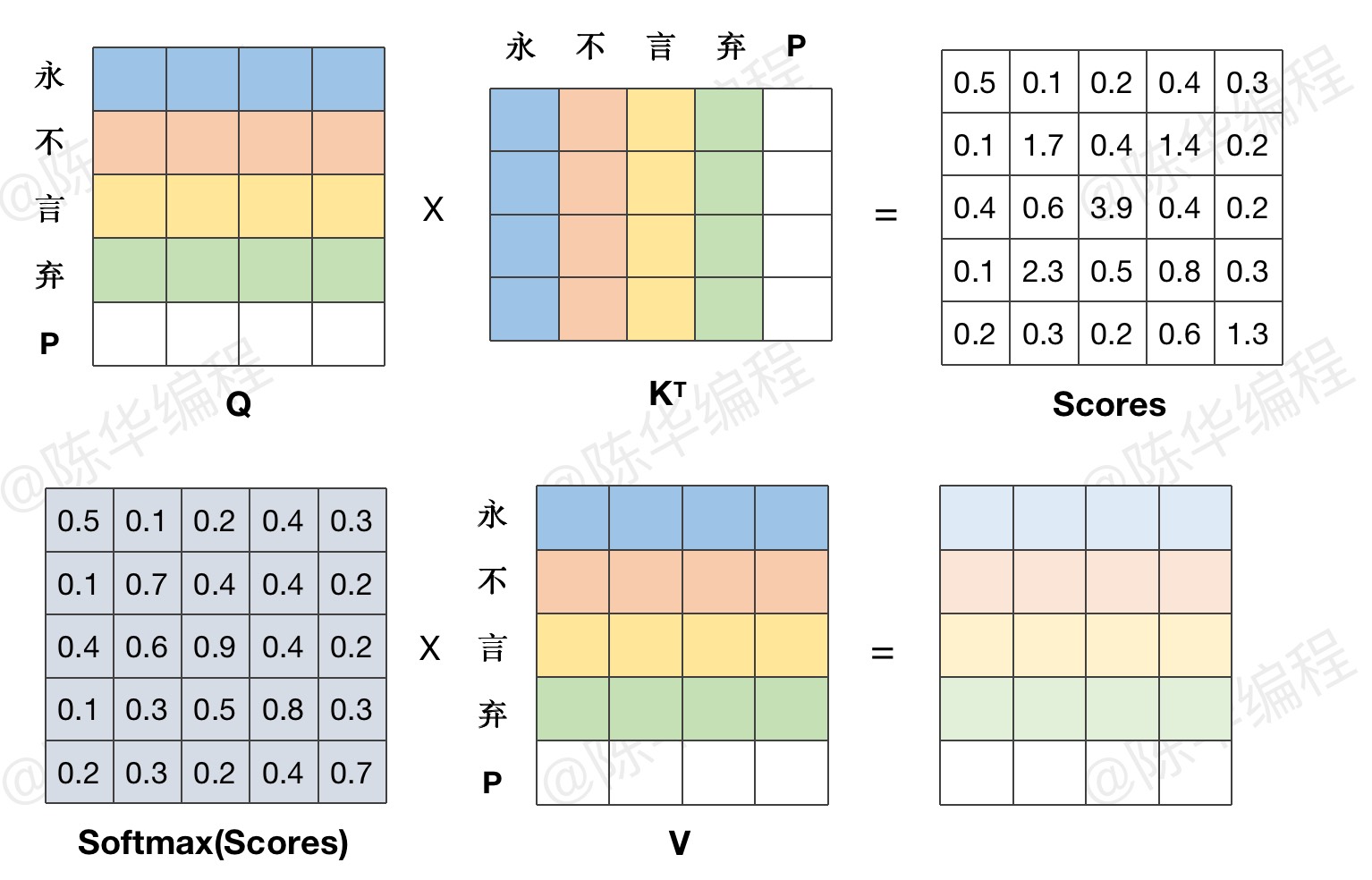
4、Masked Attention
用掩码的方式,模拟逐字生成的过程。

5、Encode-Decode Attention
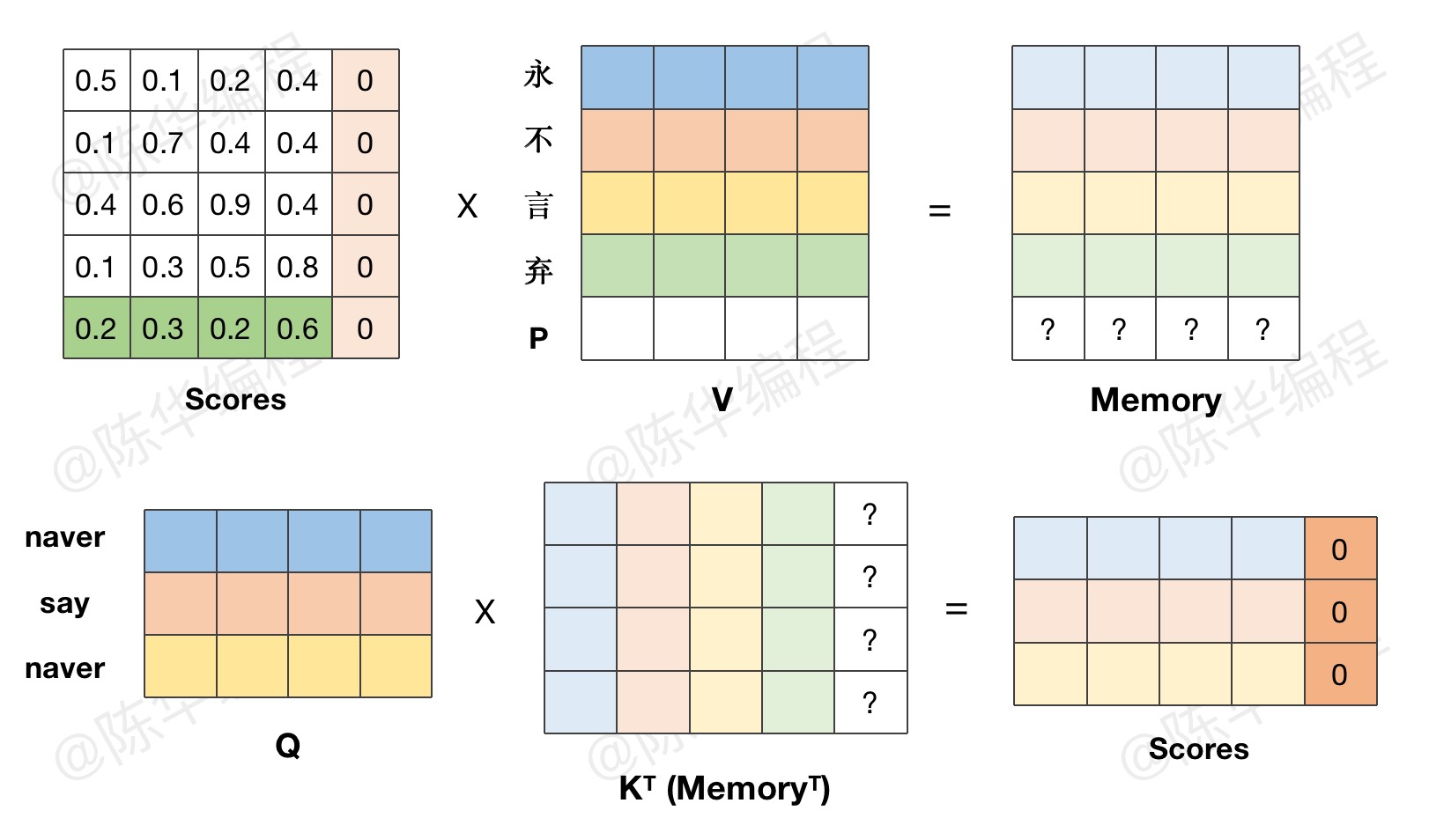
那到现在为止,关于 Transformer 模型结构的理论讲解,也只能到这个程度了。不动手写代码,肯定是无法完全理解模型结构的。所以接下来,我们就带着疑问,去逐层复现模型代码。
本文链接:http://www.ichenhua.cn/edu/note/650
版权声明:本文为「陈华编程」原创课程讲义,请给与知识创作者起码的尊重,未经许可不得传播或转售!



