Pytorch BERT_TextCNN P1 新闻文本分类项目介绍
从本节课开始,我将带大家来完成一个《Bert+TextCNN新闻文本分类项目》。文本分类是自然语言处理最基础,也是最重要的任务之一,非常适合作为NLP入门的第一个项目。
数据集和效果演示
1)数据集:清华大学的 THUCNews 新闻文本分类数据集(子集),训练集18w,验证集1w,测试集1w
2)10个类别:金融、房产、股票、教育、科学、社会、政治、体育、游戏、娱乐
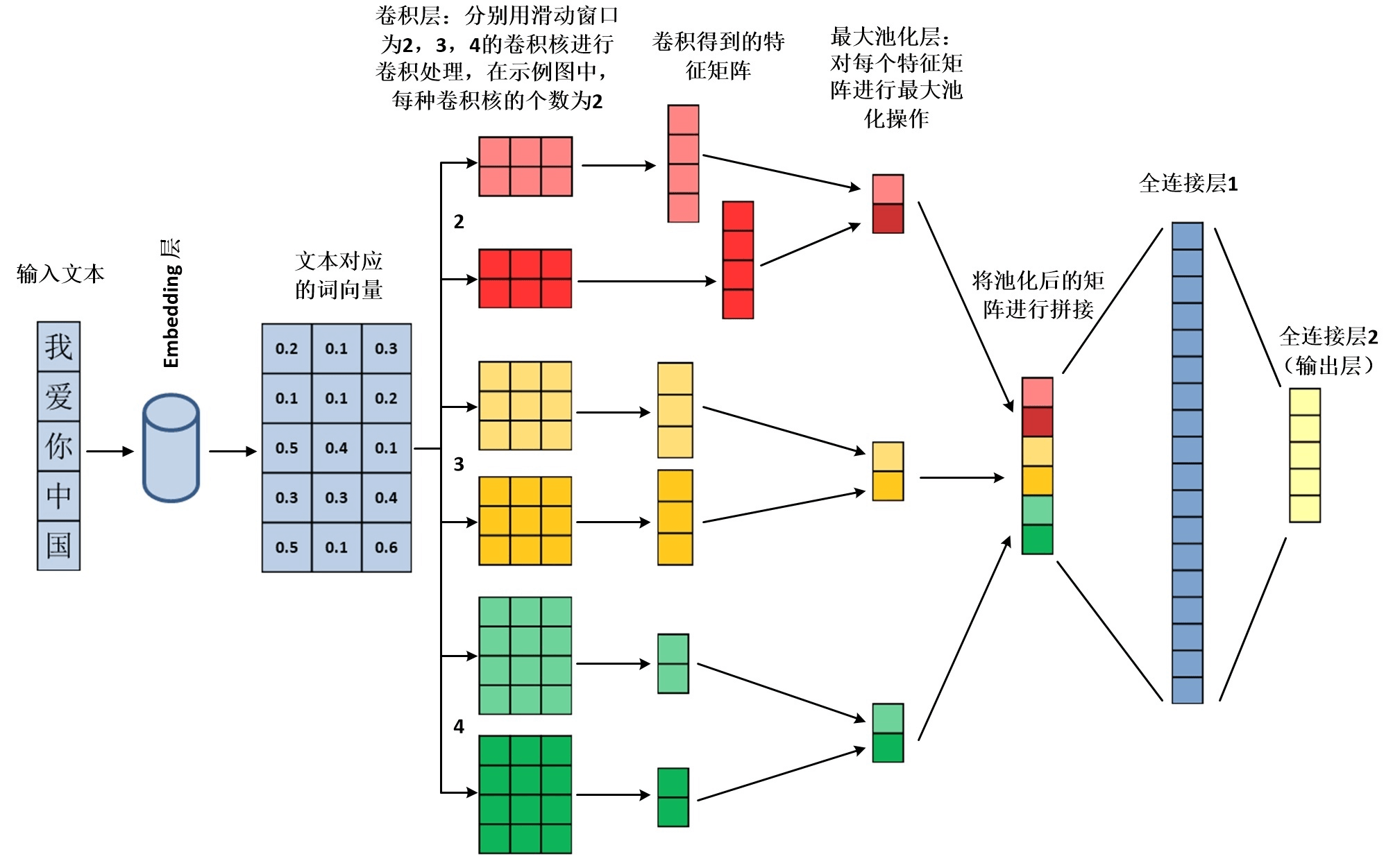
模型结构
在这个课程里,我选用的是 TextCNN 这个模型,来完成分类任务,并不是说只能用 TextCNN,选用其他模型比如 RNN、LSTM 都是可以的。只是因为我有一个小小的野心,就是准备做一个 NLP 的系列项目课程,用尽量不同的模型来完成不同的项目,把常用的模型都覆盖到。同时,TextCNN 也是面试经常会问到的一个基础模型,希望大家学完这个课程之后,能够基本掌握这个模型结构。
另外,大家看到标题里面,在 TextCNN 之前,还接了一个 Bert 模型,这是因为和随机向量化对比,使用 Bert 之后,模型准确率从 0.9 提升到了0.92,准确率有两个点的提升,所以选用了效果更好的模型结构,给大家做讲解。
补充说明
1)虽然 TextCNN 模型结构简单,但如何把代码写的简练,还有很多细节值得琢磨。
2)因为用到 Bert 预训练模型,计算量很大,后面会介绍白嫖 Kaggle GPU 资源,来进行模型训练的方法,敬请期待。
本文链接:http://www.ichenhua.cn/edu/note/502
版权声明:本文为「陈华编程」原创课程讲义,请给与知识创作者起码的尊重,未经许可不得传播或转售!



